



Introduction
Computer vision has vastly improved throughout the years. During this time, the introduction of convolutional neural networks has made computer vision tasks such as tailored multimedia content synthesis considerably easier.1,2 Despite this, determining the sort of movie by looking at the posters on the neural network has not proven very successful.
In the film-making process, a movie poster is quite important. It’s more than a mere visual; it’s a well-thought-out distribution and promotional tool intended to convey the film’s overall message. Furthermore, the poster provides vital information about the film by utilizing rich visual aspects such as the title, lead characters (actor/actress), plot, genre, and others.3–5 The posters are created using a set of predetermined guidelines for layout, color, typeface, and composition. The guidelines may vary depending on the genre and audience. A movie title, for example, might convey genre information based on the color it is composed of; romantic movie titles use light blue and pink colors.
The genre is one of the most important aspects of a film and can be a deciding factor in the decision-making process. The film’s genre can provide general information and a broad overview of the film. As a result, movie genre classification is one of the most difficult challenges in computer vision.6 Several distinct strategies based on diverse movie data (such as storylines, trailers, and posters) have been utilized singly or in combination to execute genre classification efficiently in prior studies,6 as represented in Figure 1.

The movie narrative is constrained in that it only depicts the first half of the primary plot, not the complete story. Meanwhile, trailers provide detailed information in the form of videos, but due to their vast data size, they demand a lot of processing resources to classify the movie genre.2 Movie posters, on the other hand, are created as a single image with tiny size and ratio, using less processing resources and being easier to produce.
Accurate movie genre classification has become a critical component of the recommendation system. Movie posters are displayed by video streaming providers (VSPs), such as Amazon Prime Video, to show users what movies they recommend. However, because movie posters are so varied, they do not always completely justify the genre. Personalized poster generation is vital for various streaming platforms because each user has a varied interest. Netflix will create personalized artwork for subscribers to assist them to identify the content they want to watch and enhance their pleasure and retention as a result of this issue. Using still photos taken from the source video, create raw artwork. Netflix then assesses these photographs to ensure that they appropriately represent your content in terms of aesthetics, ingenuity, and variety of items. This results in meaningful, individualized artwork depending on the interests of each member.7–9 The method we propose addresses similar challenges by categorizing photographs into distinct genres based on aesthetics. Because our method categories movie genres solely based on movie posters, it may be utilized to generate individualized feedback based on member recommendations.
The multi-label movie genre classification using movie poster photos is presented in this research article. Feed-forward in the deep learning discipline, the InceptionV3 convolutional neural network (CNN) has been used to extract information about the style of an image for tasks such as style transfer. The trained CNN model extracts movie poster features to the feature map and uses them as a weight to focus on the characteristics of each genre in the poster. When compared to previous algorithms, it does a superior job at classifying different movie genres. By crawling the IMDB website, we obtained the overall 36,423 movie posters from 28 different genres. The obtained movie poster dataset was subsequently used to train our model for multi-label genre categorization. The program forecasts the top three classes with the greatest likelihood of seeing a specific movie poster
The remainder of this work is structured as follows. The background of the poster-based movie genre classification methods along with non-poster-based movie poster classification approaches is briefly described in Section II. Section III explains the proposed method. Concluding this research article, section IV describes the overall performance evaluation and discussion of the proposed method.
Related Work
Many researchers have attempted to categorize film genres from image posters using machine learning and deep learning. This section compares and contrasts studies that used movie posters to categorize genres and those that did not.
Poster-based movie genre classification
https://insights.aib.world/article/29714-letter-from-the-editors-special-forum-on-managing-reputation-across-borders?auth_token=IAmDKs59Aj86YW6MN6o-
The poster is a representation of numerous aspects of the film/movie. As a result, the poster can be used to extract numerous features of the film. Color histograms and GIST image descriptors were used to extract low-level visual properties such as poster colors and edges.10 In lvarez et al.11 traditional machine learning approaches were used to classify the genres. Multiple label data was classified using the multi-label k-nearest neighbor approach and the random K-label set methodology. The naive Bayes classifier was also used to classify single label data. In a similar study,12 properties such as color, edges, and texture were retrieved from the poster. Apart from using low-level data like color, borders, and textures, the number of people’s faces on the poster was also used as a classification characteristic. A vector space model was also used to extract the summary text features.13 Based on the qualities and keeping the literature for the overview of the poster, a Support Vector Machine (SVM) was used to classify the poster into genres. However, the number of genres is restricted to four, and there are no multiple label classifications. The majority of the studies mentioned above attempted to classify genres using only a few posters.
The number of posters utilized gradually increased when deep learning was applied for genre classification.14 However, rather than relying solely on deep learning models, numerous studies have combined traditional machine learning approaches with statistical multi-label methods.11 The Chu and Guo15 used convolutional networks on poster images to do genre categorization beyond existing machine learning approaches. We also employed additional criteria, such as object detection from poster images, to classify genres. A total of 23 genres have been defined for poster genre classification, which is greater than prior studies. Furthermore, this technique outperformed other machine learning techniques. Since then, investigations based only on deep learning, such as transfer learning have been done in Kundalia, Patel, and Shah.14
Non-poster-based movie genre classification
Other futuristic information, such as trailers and synopses offering information about the film, was used to identify the genre in addition to the poster. Image frames and audio information, in particular, are found in movie trailers, which provide a variety of movie-related qualities. As a result, numerous recent studies have classified genres using trailers. The use of low-level elements in movie trailer categorization has been explored in the same way that poster-based genre classification has been.2 In addition, genre classification based on trailer information is performed using a CNN.16 A trailer dataset for genre classification has been created. However, there were only four genres available, and various label classifications were not considered. In addition, CNN’s have been developed for data expansion at the scene level and motion recognition, such as histograms.
Similarly, Wehrmann and Barros6 ought to categorize trailers using convolutional networks. Furthermore, their research employed residual connections to construct a time convergence network for multi-label movie genre classification. Genre classification using movie synopses and synopses is being actively carried out with the advancement of natural language processing research.17 Ertugrul and Karagoz18 employed bidirectional long- and short-term memory to classify movies into genres based on story summaries. The number of genres was limited to four and only one label classification was utilized. Another study presented a self-attention network for identifying multiple labels based on an overview19 for classifying multiple labels. There are numerous examples of genre categorization utilizing various movie-related data, and research is also underway to define genres using posters.13 However, this treatise focuses only on poster data. A poster is simple to handle because it provides multiple types of information in one image, and it is also one of the primary data sources in most movies.
This research, on the other hand, concentrates on the broad classification of single-label images. This work focuses on input tensors while applying transfer learning to extract style traits, which was inspired by a previous study. This study focused on the relationship between style traits in posters from different genres, allowing for more precise genre classification. This approach is described in greater detail in the following section.
Proposed Method
This section looks at the dataset that was reconstructed for the multi-label genre classification job, followed by the proposed method’s overall implementation.
Dataset
Movies contain many data types such as posters, plots, star ratings, and the images themselves. As a result, movie datasets have emerged as one of the most essential datasets for machine learning, and deep learning applications are taken from existing databases. Movie posters can be found in MovieLens and Kaggle’s movie datasets as well.
Using existing movie datasets for poster-based genre categorization is a difficult task. For starters, the existing collection contains a large number of films from the 1800s. A movie poster from this era should be removed if it is described as “an image intended to be displayed in the theatre during the presentation” rather than “an image representing a movie.” In real-world databases, movie posters from this era frequently lacked visuals or were simply movie stills. Because the construction of movie posters by genre was established in the late twentieth century, movies from the late twentieth century to the early twenty-first century could increase the accuracy of poster-based genre categorization if they make up the majority of the dataset.
Therefore, overcoming this problem, this study reassembled the movie dataset for the poster-based genre classification. To begin, IMDB poster images were crawled in order of box office revenue by genre to find common poster elements associated with the category. Films having a score of less than 50 were not considered. Then, using the IMDB genres and guideline definitions, 28 subjective genres were created. There have been 36,423 movie posters gathered in all.
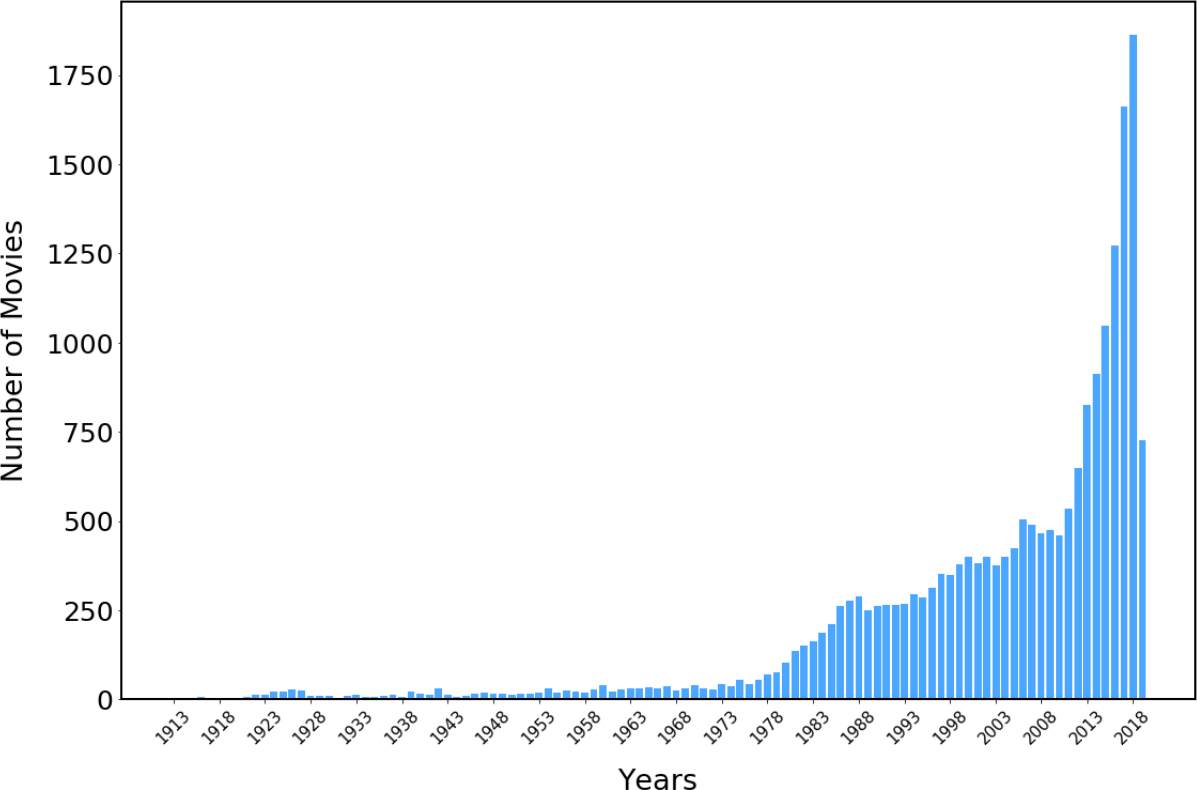
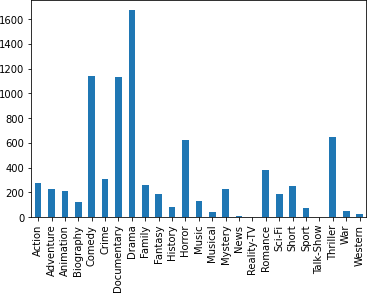
The sample posters in the dataset used in this study are from films released in the late 1990s and early 2000s, as shown in Figure 2. Figure 3 and Figure 4 depict specific statistics from the poster dataset that was gathered. The drama genre has the highest percentage of posters, as shown in Figure 3. This could be due to the diversity of genres.



Proposed Feed-forward CNN
The ability to transfer knowledge is one of the most important factors in deep learning advancement. Transfer learning tries to create a framework for applying previously learned skills to solve new issues considerably more quickly and efficiently.20 Pre-trained models that have been trained on big datasets are used in transfer learning. According to the revised problem definition, these models will be reused. Large datasets are used to train pre-trained models. For instance, the start is trained on ImageNet, which contains approximately 14 million photos organized into 1000 classes and can be used to tackle different problems. As a result, these models are sufficiently generalizable. Because of its ability to generalize, transfer learning is widely employed in computer vision. These models are trained over a long period, necessitating a lot of computing power. We used a beginning model to extract greater degrees of characteristics in movie posters due to restricted computer resources.
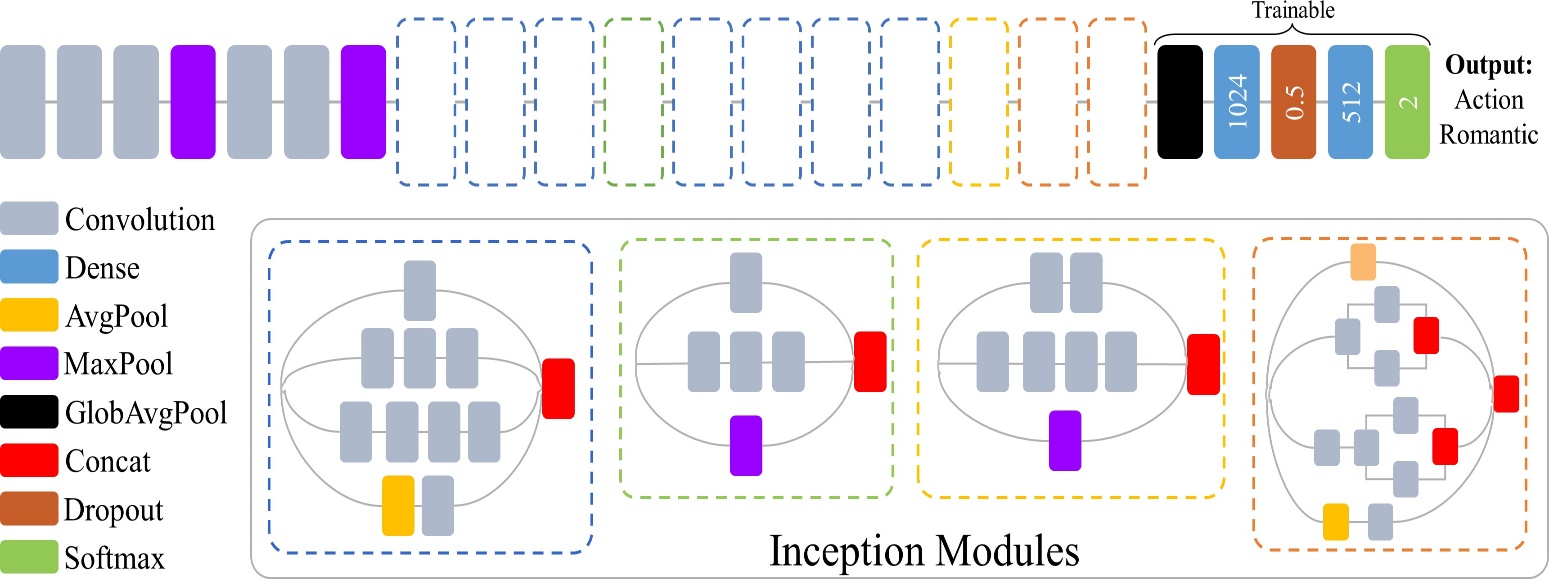
The authors21,22 utilized a pre-trained InceptionV3 model with ImageNet weights to extract greater levels of features from the poster. The initial model is made up of a succession of convolutional layers that are used to extract features. The pre-trained model’s top (output) layer has been removed, leaving a stack of completely connected high-density layers. The model was employed in these dense layers to create movie genre classifiers. The proposed model architecture is shown in Figure 5. The rectifier linear (ReLu) activation function is used in each high-density layer, which includes 128 neurons. With 28 output nodes, the output layer is dense. SoftMax activation is available on this layer. Each instance in the dataset used to train the model has a 200×150×3 feature shape. Each label instance has a dimension of 1×12 Where 28 corresponds to the expected number of classes.

A training set of 36,423 photos was used to train the model. Each image is an RGB image with a size of 200×150 pixels. We split the dataset into three parts portions train 70%, validation 20%, and test 10%. The train part contains 25,495 movie posters, and verification and testing include 9834 and 1093 movie posters, respectively. We use data augmentation to overcome the overfitting problem in the training process. Before being supplied as input to the network, all photos are preprocessed by first clipping the core area and then scaling them to 218×178 pixels. Shear transformations at 30° and 20° angles, random rotations, random horizontal inversion, and horizontal and vertical shifts of 0.2 of the images are performed, respectively. The stochastic gradient descent with weight decay (SDGW)23 optimization algorithm with the learning rate of 0.01 and momentum of 0.9 is used to improve the efficiency of the model. An early stop mechanism with the patience of 10 is used in the experiment. The data is provided in a mini-batch with a size of 32 and a learning rate of 0.001 to minimize costs. One thousand epochs are performed to train the sequence pattern of the data. The GeForce RTX 2080 Ti GPU and Keras API with a Tensorflow backend using Python language are used for deep feature extraction.
Experiments and Results
The project employed a dataset of 36,423 movie posters from movies published between 1913 and 2019. Also, there are 25,495 training photos, 9834 validation images, and 1093 test images were used. Figure 6 shows a sample multi-hot vector with seven poster entries. The data was not normalized because we planned to use a pre-built Keras model with pre-input processing capabilities.

In this study, we will carry out the experimental InceptionV3 as a bottleneck model. For each model, 40 epochs of training were performed to prevent overfitting. Because overfitting is likely to occur at baseline, we used early halting based on the correctness of the training. We used the stochastic gradient descent method with weight decay23 as the optimizer and set the learning rate to 0.01. Binary cross-entropy employed the loss function. The baseline model was in the form of a multi-label classification job, and the number of predicted labels extracted was the same as the number of ground truth labels in the movie poster.
Results
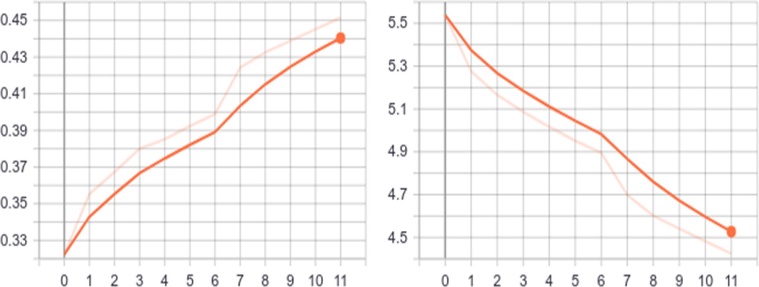
The trained deep feedforward network is used to recognize the genre of the movie from its poster image. The proposed model using the SGDW optimizer algorithm gets the validation of 33.5% and training of 36.73 accuracies on 2 epochs. Meanwhile, the model achieved 82.5% accuracy on the test split of our dataset. Out of 1093 instances in the test dataset, our model correctly predicted at least one genre in 901 instances. On the training data, Figure 7 displays accuracy and loss. Table 1 and Table 2 performance of the proposed method in comparison with other well-known feed-forward networks.

Our model performs better than other implementations with pure precision. Nevertheless, the inclusion of key metrics such as recalls and all-matches provides insight into future improvements and model performance of these models. To get a direct understanding of precision, recall, and F1. The score presents the following formulas.
The recall is considered to be the most important of these three metrics for classification tasks. This was our personal goal to correctly identify the same number of genres as possible.
Accuracy=TP+TNTP+TN+FP+FN
Precision=TPTP+FP
Recall=TPTP+FN
F1=2×Precision×RecallPrecision+Recall= 2×TP2×TP+FP+FN
Our model performs better than other implementations with pure precision. Nevertheless, the inclusion of key metrics such as recalls and all-matches provides insight into future improvements and model performance of these models. To get a direct understanding of precision, recall, and F1. The score presents the following formulas.
Figure 8 depicts some examples of movie posters categorized using the proposed method. Our model correctly identified at least one of the actual genres in the first three instances and the fourth instance. The model predicted two correct genres from the original genre. The model predicts the top three classes with the highest probability of a particular movie poster.

Discussion
The following are some of the highlights of the findings: In the second row, we discovered that the poster for the action genre centered on weapons such as guns and knives. In the adventure genre, the main attention was on poster characters. In the animation genre, we focused on the characters and titles that showed the animation. The fantasy genre also focused on characters. The comedy and drama genres were interpreted as the two broadest genres, as they generally focus on people and mood. The horror, mystery, and thriller genres accentuated the poster’s dark emotions as a whole, creating a frightening environment. This might also be viewed as an emphasis on the poster’s background, which reflects the environment. In the case of romance, the majority of the posters featured men and women, with an emphasis on the characters. The scenery and figures that symbolize the poster’s atmosphere were emphasized in the Sci-Fi genre. As a result, we can observe that different genres of posters are classified not only by the same section of the poster but also by the part of the poster that defines each genre.
In future work, we will include the YOLO algorithm in the model to identify individual objects in the poster that can be associated with a particular genre. In addition, the performance of our model will be improved by balancing our dataset. Finally, we intend to implement the efficiency of the proposed method with other high-performance CNN architectures, such as EfficientNet and MobileNet. Additionally, the proposed method can be adopted in smartphone devices.28,29 Additionally, the proposed deep neural network can be used for other real-time applications such as vehicle classification.30–32
Conclusion
The assessment of a movie’s genre from its poster is a quite challenging issue in computer vision, because of the high level of variability and the lack of pattern formation. This paper presents a movie genre classification from movie posters using deep neural networks. To evaluate the proposed method, we collect a large movie poster dataset consisting of 36,423 different movies belonging to 28 different genres. The evaluation results showed that the proposed model achieved promising performance. In the future, we plan to improve classification performance by incorporating more information and leveraging rich metadata.